QLORA: Efficient Finetuning of Large Language Model (Falcon 7B) using Quantized Low Rank Adapters
Finetuning open source Large Language Models like Falcon 7B on domain data with less than 15 GB of VRAM GPU using Quantization of Low Rank Adapters
👨🏾💻Github | Linkedin | GEN AI Chat GPT Detailed Architecture | Langchain QA | Transformers
Generative AI Models or Large Language Models (LLM) such as OpenAI’s GPT or Falcon 40B are taking the world by storm. In my Recent post on Chat GPT Detailed Architecture ,We have covered the detailed Architecture study on Transformers and GPT3.5 Turbo based models. In this post we’ll focus on how Finetuning and Inferencing of these LLM can be done on Small GPU machines using Quantized LORA.
Introduction
Generative AI models or LLM are known to be large, and running or training them in consumer hardware is a huge challenge for users. At the time of this writing, Falcon has 40 Billion parameters, PaLM has 540B parameters, GPT-3, and BLOOM have around 176B parameters, and we are trending towards even larger models. Therefore, these models are hard to run on easily accessible devices. For example, just to do Inference on BLOOM-176B, you would need to have 8x 80GB A100 GPUs. To Finetune BLOOM-176B, you’d need 72 of these GPUs. To fine-tune Falcon-40B models you would need 90 GB of VRAM. It is very difficult to do Inference or finetune these LLM that's where QLORA and LORA Rescue. With Help of QLORA we can Finetune or Run These LLM even on smaller VRAM. Before we get into the QLORA and LORA Paradigm and finetune Falcon 7B lets us understand various techniques for compressing these LLM.
Quantization- Way to Compressing LLM’s
As we know Gen AI models or LLM require so many GPU to run. There are ways to reduce these requirements while preserving the model’s performance. So far various technologies have been developed that try to shrink the model size, you may have heard of quantization and distillation, and there are many others.
Quantization refers to the process of reducing the precision of numerical values while retaining their essential information or in simple we can say Through Quantization we can reduce the model size. Quantization involves converting the high-precision floating-point parameters and activations of a neural network into lower-precision fixed-point or integer representations. In LLM Quantization addresses these challenges by reducing the memory requirements and computational complexity of language models, making them more efficient for deployment on resource-constrained devices. Let us understand in detail
Lets start with the basic understanding of different floating point data types, which are also referred to as “precision” in the context of Machine Learning. The size of a model is determined by the number of its parameters, and their precision, typically one of float32 (FP32), float16 (FP16) or bfloat16.
FP32 — -> 8 bits for “Exponent”, 23 bits for Mantissa, 1 bit for the Sign.
FP16 — ->5 bits are for the exponent,10 bits are for mantissa
This makes the representable range of FP16 numbers much lower than FP32. This exposes FP16 numbers to the risk of overflowing (trying to represent a number that is very large) and underflowing (representing a number that is very small).
In the Deep learning FP32 is called full precision (4 bytes), while BF16 and FP16 are referred to as half-precision (2 bytes). On top of that, the int8 (INT8) data type consists of an 8-bit representation that can store 2⁸ different values (between [0, 255] or [-128, 127] for signed integers).While, ideally the training and inference should be done in FP32, it is two times slower than FP16/BF16 and therefore a mixed precision approach is used where the weights are held in FP32 as a precise “main weights” reference, while computation in a forward and backward pass are done for FP16/BF16 to enhance training speed. The FP16/BF16 gradients are then used to update the FP32 main weights.
The half-precision weights often provide similar quality during inference as compare to FP32 main weights, which halves the model size. It’d be amazing to cut it further, but the inference quality outcome starts to drop dramatically at lower precision. To remediate that, 8-bit quantization was introduced. This method uses a quarter precision, thus needing only 1/4th of the model size! But it’s not done by just dropping another half of the bits.
Quantization is done by essentially “rounding” from one data type to another. The two most common 8-bit quantization techniques are zero-point quantization and absolute maximum quantization. First, these methods normalize the input by scaling it by a quantization constant.
For example, let’s assume you want to apply absmax quantization in a vector that contains [1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4]. You extract the absolute maximum of it, which is 5.4 in this case. Int8 has a range of [-127, 127], so we divide 127 by 5.4 and obtain 23.5 for the scaling factor. Therefore multiplying the original vector by it gives the quantized vector [28, -12, -101, 28, -73, 19, 56, 127].
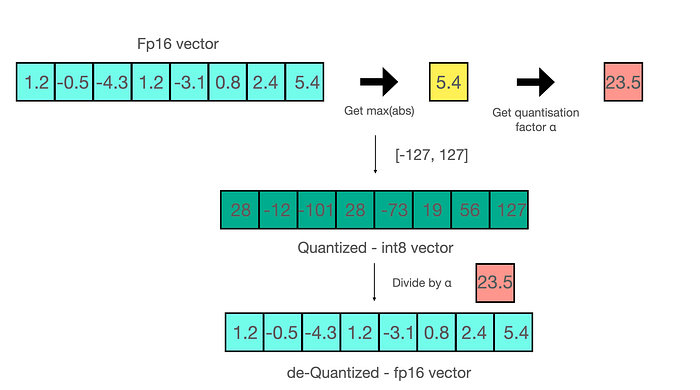
This is how Quantization is performed to reduce the model size and maintaining the performance. Also with Quantization we can have faster Inference and with less GPU usage.
LORA and QLORA Paradigm
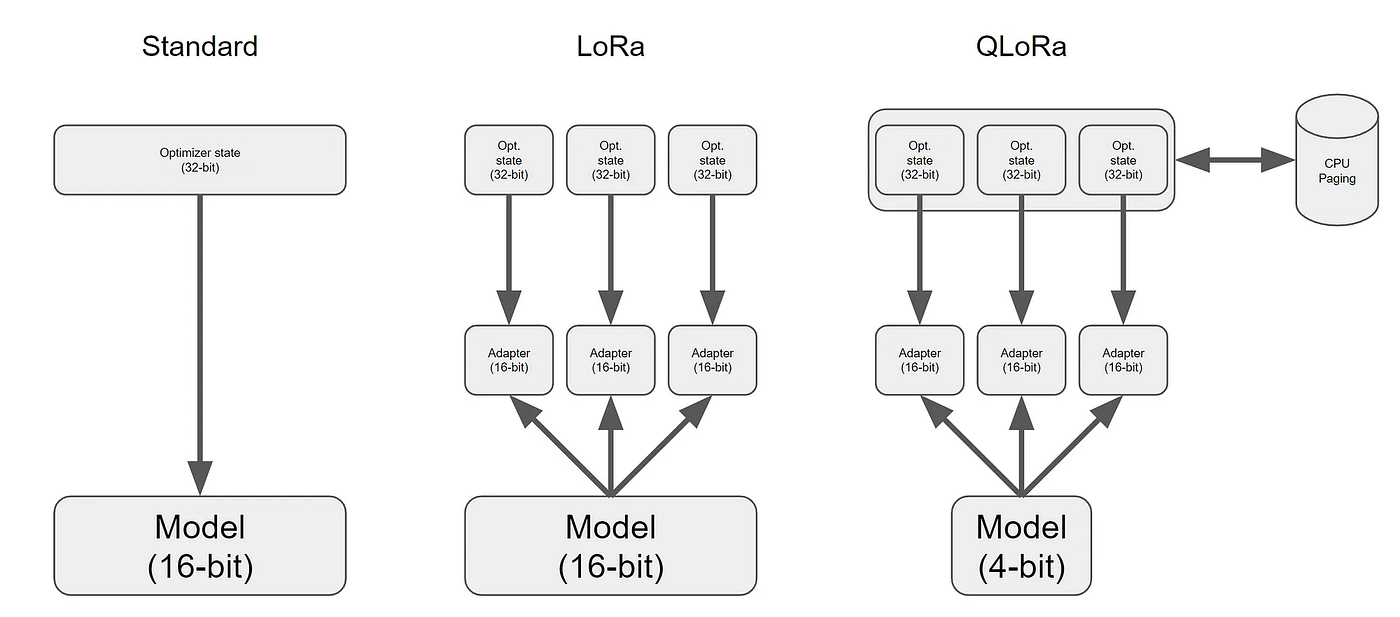
QLORA is a technique to finetune LLM on a single GPU while preserving the model performance . To understand how QLORA works we first need to understand LORA (Low Rank Adaptation) of LLM. LORA was introduced by Microsoft.`
LORA adds a small amount of trainable parameters, i.e., adapters, for each layer of the LLM and freezes all the original parameters and activations. For fine-tuning, we only have to update the adapter weights which significantly reduces the memory footprint, leaving the pre-trained weights untouched. This procedure not only reduces the size of the file post-fine-tuning but also ensures the performance or accuracy of the model remains uncompromised. LORA can reduced the trainable parameters by 10000 times and GPU memory requirement by 3 times.
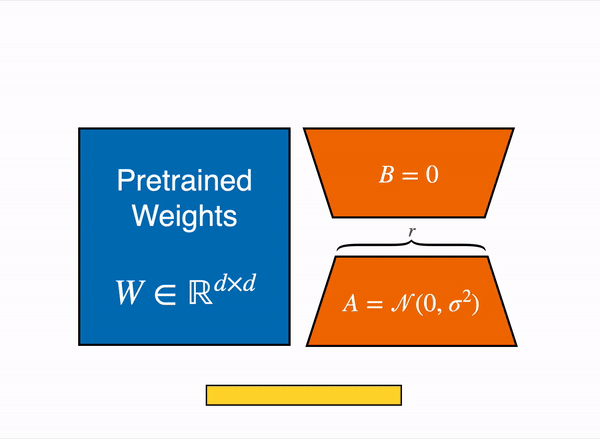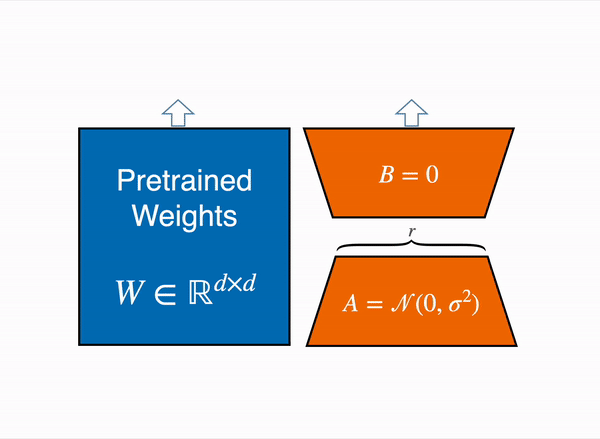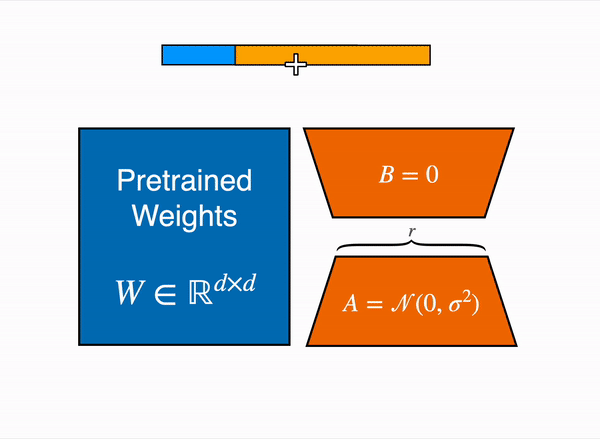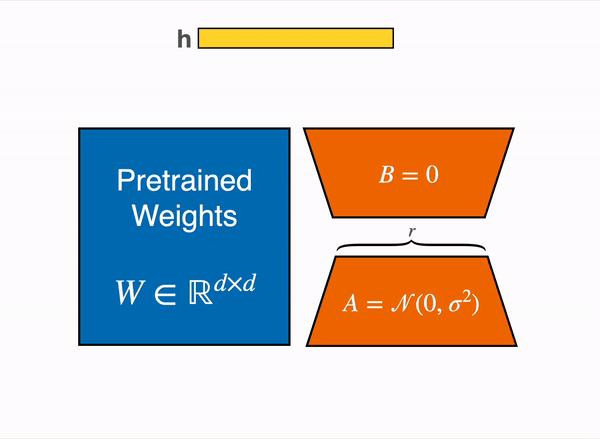
Expanding on the principles of LORA. QLORA or Quantized version of LORA introduced recently by university of Washington which goes three steps further by introducing:
- 4-bit quantization
- Double quantization to reduce model size:- Double Quantization to reduce the average memory footprints by quantizing the quantization constants.
- Paged optimizers to manage memory spikes :- Idea is to pass in from GPU to CPU some types of memory blocks, if GPU is out of memory
This remarkable technology allows the training of an enormous 65 billion parameter model on a single GPU with a memory of just 48GB, all while preserving the complete 16-bit fine-tuning task performance. QLORA backpropagates gradients through a frozen, 4-bit quantized pre-trained language model into Low-Rank Adapters (LORA).

Finetuning Falcon 7B on Dataset using QLORA
The Falcon models are state-of-the-art LLMs. They even outperform Meta AI’s LlaMa on many tasks. Even though they are smaller than LlAMa, fine-tuning the Falcon models still requires top-notch GPUs. To fine-tune Falcon-40B models without QLORa you would need 90 GB of VRAM. With QLORa, we reduce the VRAM requirements to 45 GB and less than 10GB, respectively for Falcon-40B and Falcon-7B. For Falcon-40B, this is still a lot.
I am using colab Pro for finetuning falcon 7B on custom Data
!nvidia-smi
!pip install -Uqqq pip --progress-bar off
!pip install -qqq bitsandbytes==0.39.0 --progress-bar off
!pip install -qqq torch==2.0.1 --progress-bar off
!pip install -qqq -U git+https://github.com/huggingface/transformers.git@e03a9cc --progress-bar off
!pip install -qqq -U git+https://github.com/huggingface/peft.git@42a184f --progress-bar off
!pip install -qqq -U git+https://github.com/huggingface/accelerate.git@c9fbb71 --progress-bar off
!pip install -qqq datasets==2.12.0 --progress-bar off
!pip install -qqq loralib==0.1.1 --progress-bar off
!pip install -qqq einops==0.6.1 --progress-bar offDataset which we are going to use is of Ecommerce FAQ chatbot.
https://drive.google.com/uc?id=1u85RQZdRTmpjGKcCc5anCMAHZ-um4DUCpprint(data["questions"][0], sort_dicts=False)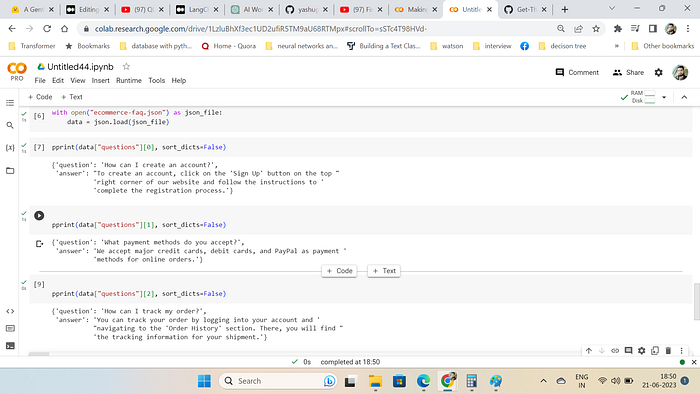
Loading Falcon model and its tokenizer
MODEL_NAME = "tiiuae/falcon-7b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
device_map="auto",
trust_remote_code=True,
quantization_config=bnb_config,
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer.pad_token = tokenizer.eos_token
Then we define the LORA config .
config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
print_trainable_parameters(model)Let do Inference before finetune on some questions and see the difference between a pretrained model output and finetuned output
%%time
device = "cuda:0"
encoding = tokenizer(prompt, return_tensors="pt").to(device)
with torch.inference_mode():
outputs = model.generate(
input_ids=encoding.input_ids,
attention_mask=encoding.attention_mask,
generation_config=generation_config,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))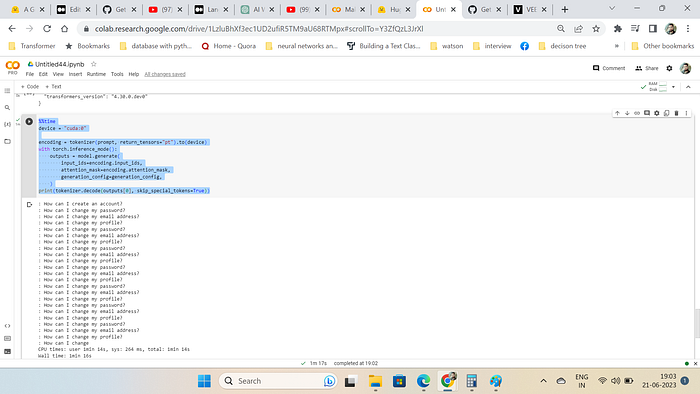
If you can see the output from the pretrained model, model is not performing well and generating random content.Let us finetune the model . First make this dataset into hugging face format supported dataset and define the training pipeline using hugging face trainer high level api.
training_args = transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
num_train_epochs=1,
learning_rate=2e-4,
fp16=True,
save_total_limit=3,
logging_steps=1,
output_dir=OUTPUT_DIR,
max_steps=80,
optim="paged_adamw_8bit",
lr_scheduler_type="cosine",
warmup_ratio=0.05,
report_to="tensorboard",
)
trainer = transformers.Trainer(
model=model,
train_dataset=data,
args=training_args,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False
trainer.train()Since we are training for 1 epoch only as its a small dataset .lets push the model to the hub and see the output.The model is available at huggingface hub and its a adapter model of 18mb in size and it refers to the falcon7b model
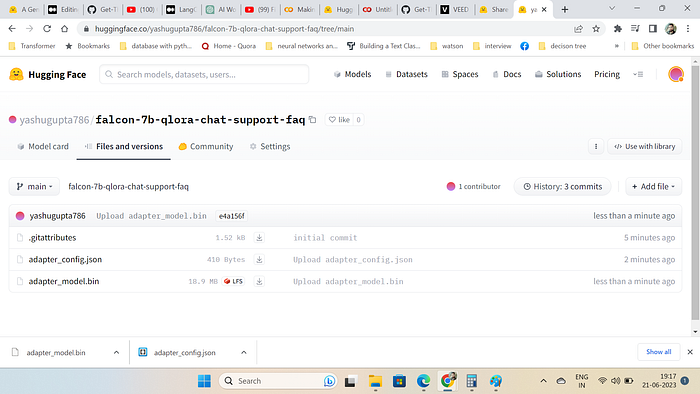
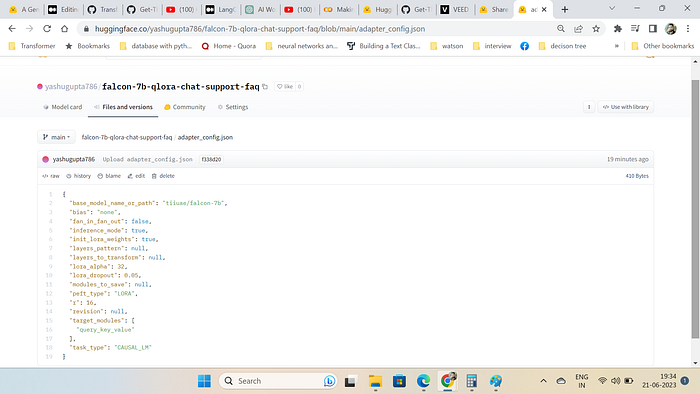
Lets load the finetuned model and see the output.
PEFT_MODEL = "yashugupta786/falcon-7b-qlora-chat-support-faq"
config = PeftConfig.from_pretrained(PEFT_MODEL)
model = AutoModelForCausalLM.from_pretrained(
config.base_model_name_or_path,
return_dict=True,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
tokenizer.pad_token = tokenizer.eos_token
model = PeftModel.from_pretrained(model, PEFT_MODEL)
%%time
prompt = f"""
: How can I create an account?
:
""".strip()
encoding = tokenizer(prompt, return_tensors="pt").to(DEVICE)
with torch.inference_mode():
outputs = model.generate(
input_ids=encoding.input_ids,
attention_mask=encoding.attention_mask,
generation_config=generation_config,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Few Screenshot for Inference Outputs
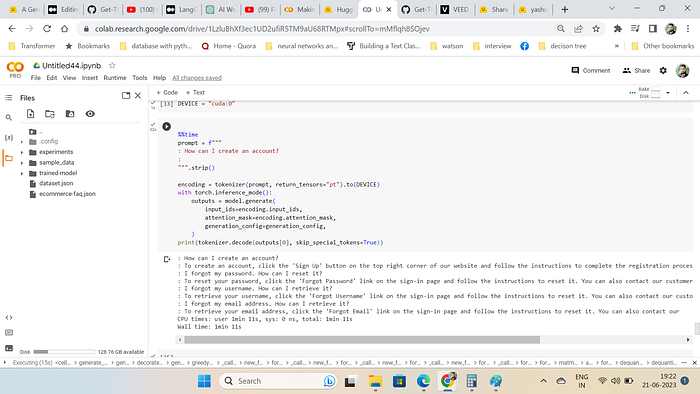
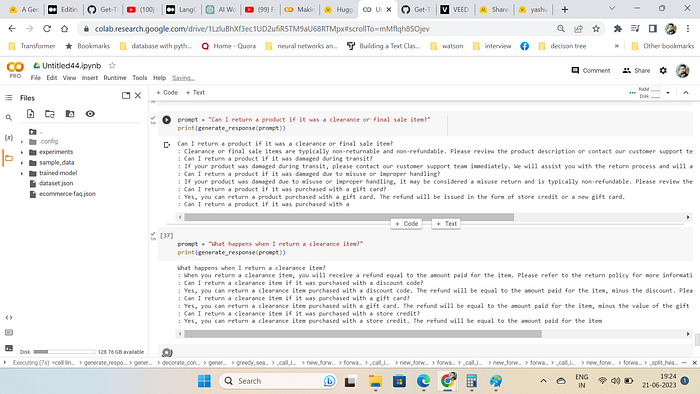
Conclusion
Hopefully, by the end of this article, we will get to know about Quantization and Finetuning of opensource Falcon 7B model
Links , references and credits
QLoRA paper: https://arxiv.org/abs/2305.14314
QLoRA GitHub: https://github.com/artidoro/qlora
LoRA paper: https://arxiv.org/abs/2106.09685
Huggingface, bits and bytes