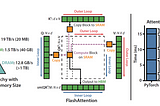
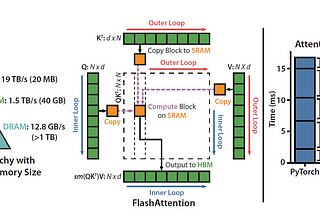
Understanding Flash Attention - Fueling Large language ModelsDetailed Understanding of Flash Attention which is getting widely used in many of the Large Language Models.Jul 25, 2023Jul 25, 2023
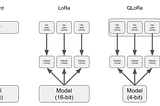
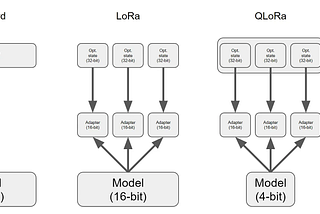
QLORA: Efficient Finetuning of Large Language Model (Falcon 7B) using Quantized Low Rank AdaptersFinetuning open source Large Language Models like Falcon 7B on domain data with less than 15 GB of VRAM GPU using Quantization of Low Rank…Jun 21, 20232Jun 21, 20232
LangChain-Supercharging Large Language Models With LC and Vector DBBuilding Document Question Answering using LLM, Langchain, Pinecone, Croma 🔗Apr 26, 2023Apr 26, 2023
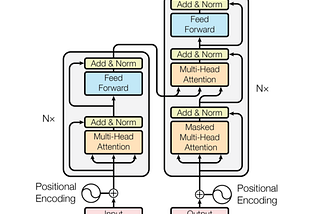
Published inNerd For TechChat GPT and GPT 3 Detailed Architecture Study-Deep NLP HorseA detailed intuition and methodology behind the GPT and Chat GPT Language Models.Mar 2, 20231Mar 2, 20231
Faster Inference for NLP Pipeline’s using Hugging Face Transformers and ONNX RuntimeTransformers are taking the NLP world by storm as it is a powerful engine in understanding the context. Nowadays with use of Transformers…Jan 3, 2021Jan 3, 2021
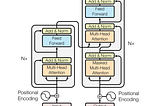
In and Out of Transformers (Attention is all you need) -Deep NLP HorseTransformer Introduction and In Depth Tutorial |Zero to Hero in Modern NLP with TransformerAug 26, 20201Aug 26, 20201